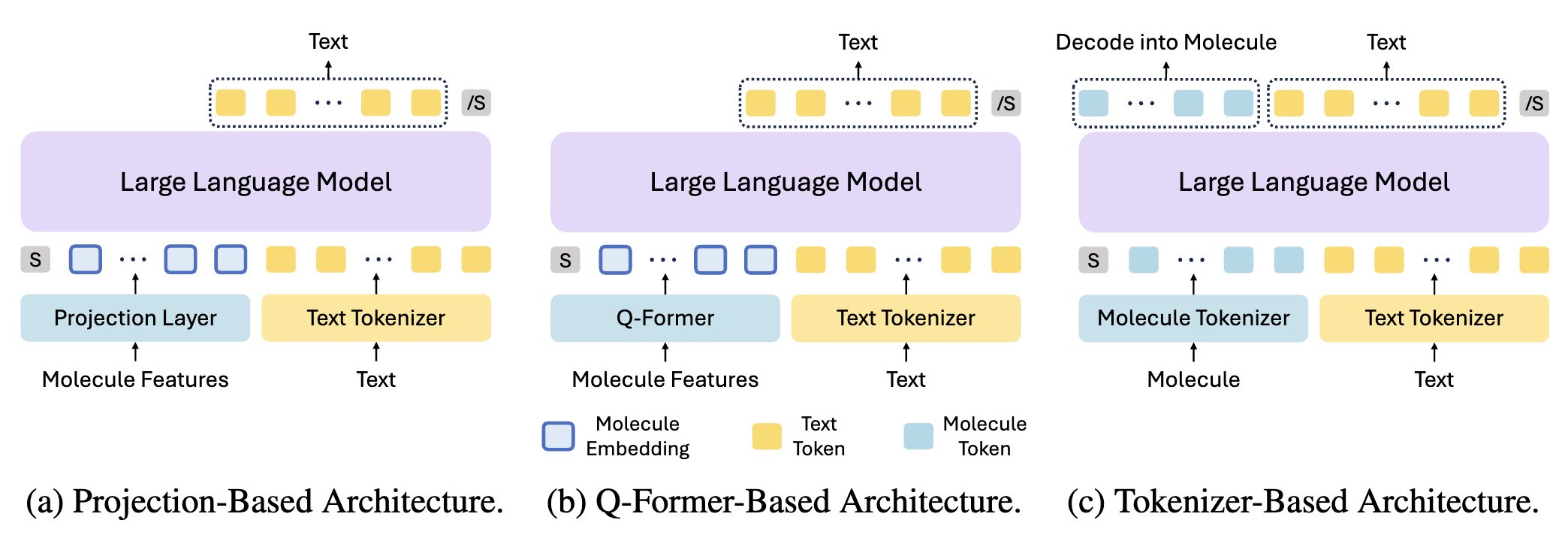
Abstract
The remarkable success of Large Language Models (LLMs) across diverse tasks has driven the research community to extend their capabilities to molecular applications. However, most molecular LLMs employ adapter-based architectures that do not treat molecule and text modalities equally and lack a supervision signal for the molecule modality. To address these issues, we introduce UniMoT, a Unified Molecule-Text LLM adopting a tokenizer-based architecture that expands the vocabulary of LLM with molecule tokens. Specifically, we introduce a Vector Quantization-driven tokenizer that incorporates a Q-Former to bridge the modality gap between molecule and text. This tokenizer transforms molecules into sequences of molecule tokens with causal dependency, encapsulating high-level molecular and textual information. Equipped with this tokenizer, UniMoT can unify molecule and text modalities under a shared token representation and an autoregressive training paradigm, enabling it to interpret molecules as a foreign language and generate them as text. Following a four-stage training scheme, UniMoT emerges as a multi-modal generalist capable of performing both molecule-to-text and text-to-molecule tasks. Extensive experiments demonstrate that UniMoT achieves state-of-the-art performance across a wide range of molecule comprehension and generation tasks.
Molecule Tokenizer for LLMs
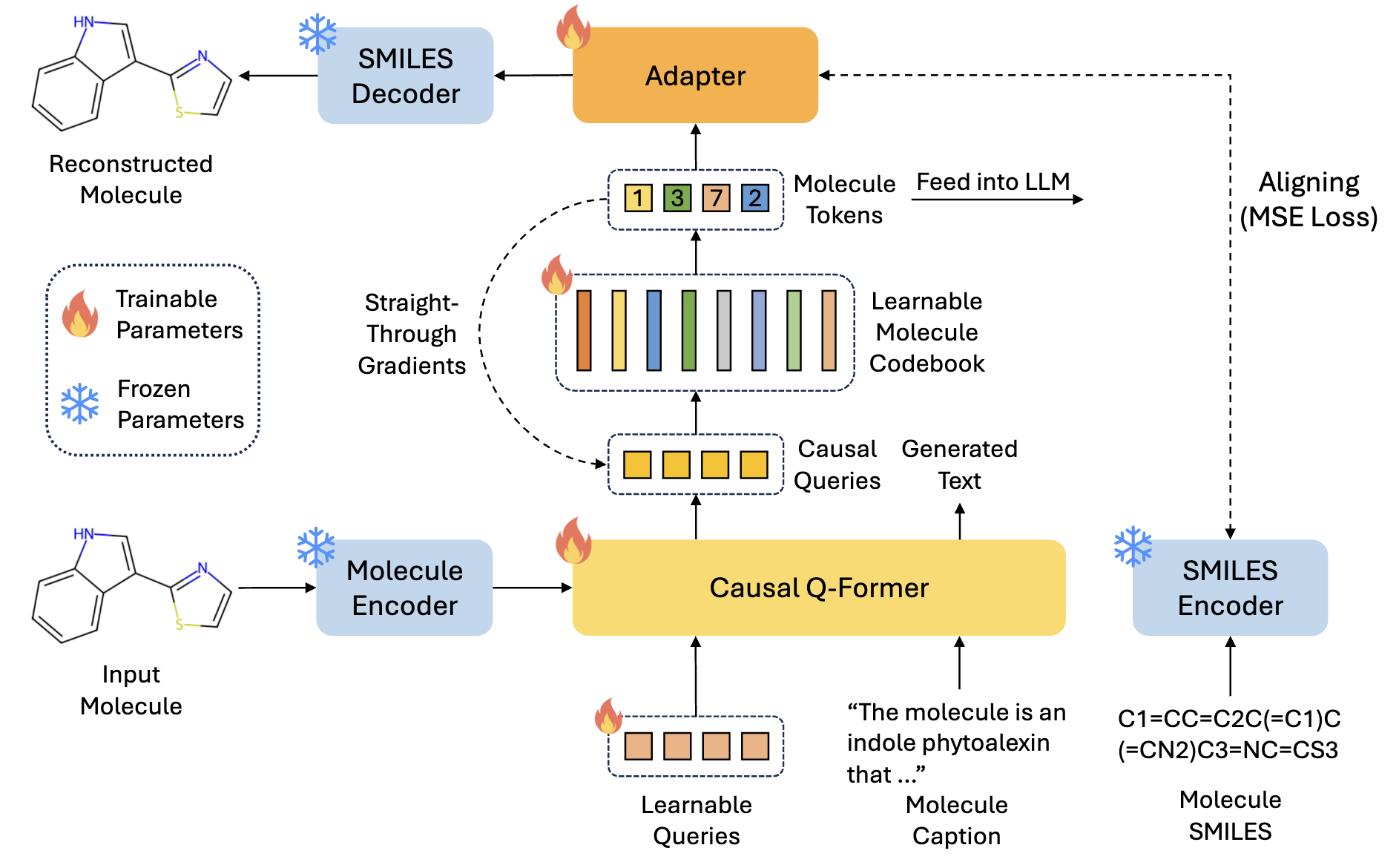
Figure 1. Illustration of our proposed molecule tokenizer.
A pivotal aspect of UniMoT's architecture is the molecule tokenizer for transforming molecules into molecule tokens. We introduce a Vector Quantization-driven tokenizer, which incorporates a Q-Former to bridge the modality gap between molecules and text. Specifically, we incorporate causal masks for the queries, enabling the Q-Former to generate a causal sequence of queries compatible with the unidirectional attention in LLMs. The sequence of queries is subsequently quantized into a sequence of molecule tokens using a learnable codebook. The molecule tokens encapsulate high-level molecular and textual information, which are then aligned with the latent space of a generative model via an MLP adapter, enabling the generation of desired molecules.
Unified Molecule-Text Language Model
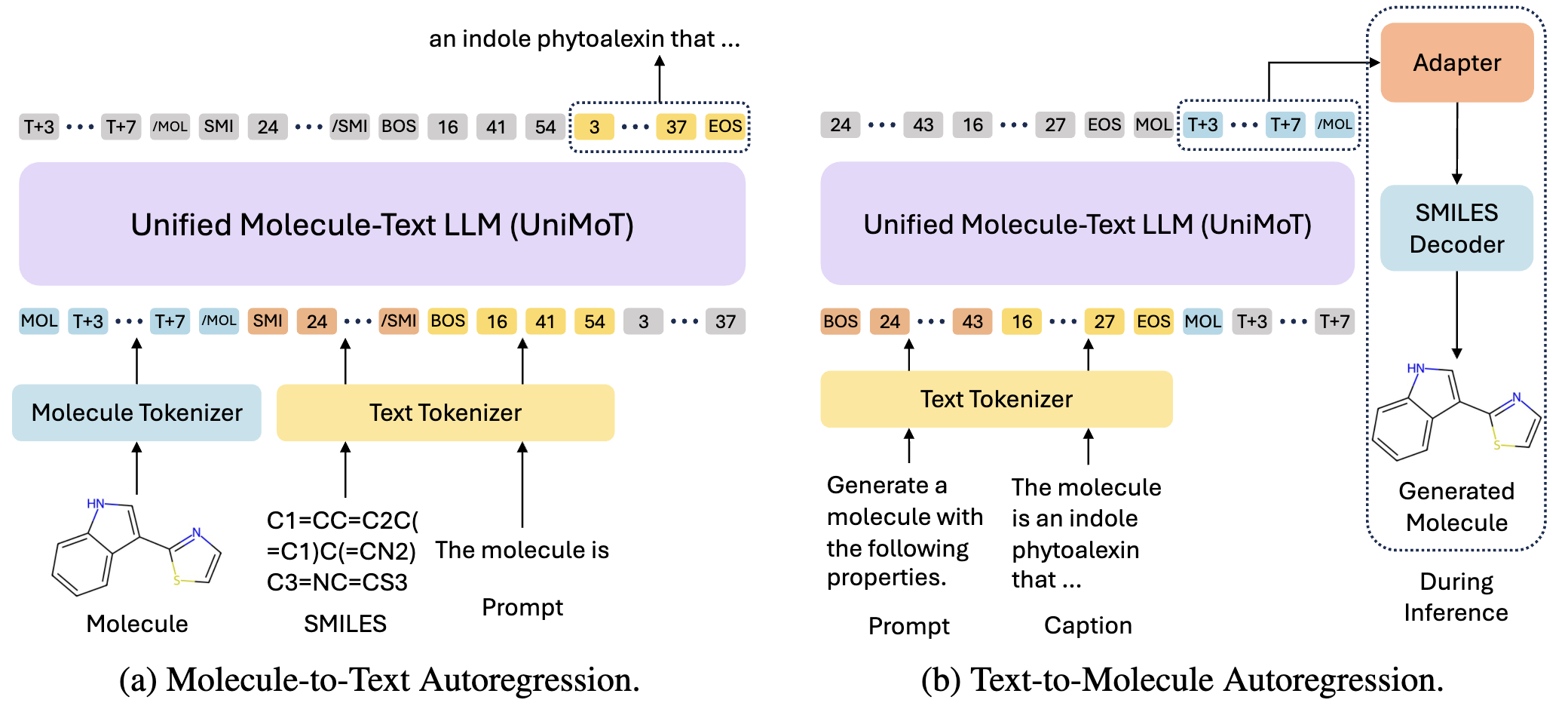
Figure 2. Illustration of the multi-modal autoregressive pretraining on molecule-text datasets.
Pretrained LLMs can integrate the molecule tokenizer by treating molecule tokens as new words and constructing a molecule vocabulary through mapping the learned codebook. We adopt the unified discrete token representation for molecules and text, coupled with the unified next-token-prediction training paradigm of LLM. This unification of representation and training paradigm enhances LLMs' ability to understand molecule-text interactions and alignment. UniMoT interprets molecules akin to understanding a foreign language, and generates them as if they were text. Following a four-stage training scheme, UniMoT serves as a multi-modal generalist capable of performing both molecule comprehension and generation tasks.
Results on Downstream Tasks
UniMoT exhibits remarkable capabilities in multi-modal comprehension and generation. Extensive experiments demonstrate that UniMoT achieves state-of-the-art performance across a wide spectrum of molecule comprehension tasks and molecule generation tasks.
Molecule Comprehension Tasks
We employ a range of molecule comprehension tasks, including molecular property prediction, molecule captioning, and molecule-text retrieval. UniMoT consistently demonstrates improvements across these tasks, showcasing its capability in aligning molecules with text. Additionally, the model's molecule tokenizer effectively generates tokens that encapsulate high-level molecular and textual information, which proves beneficial for these comprehension tasks.
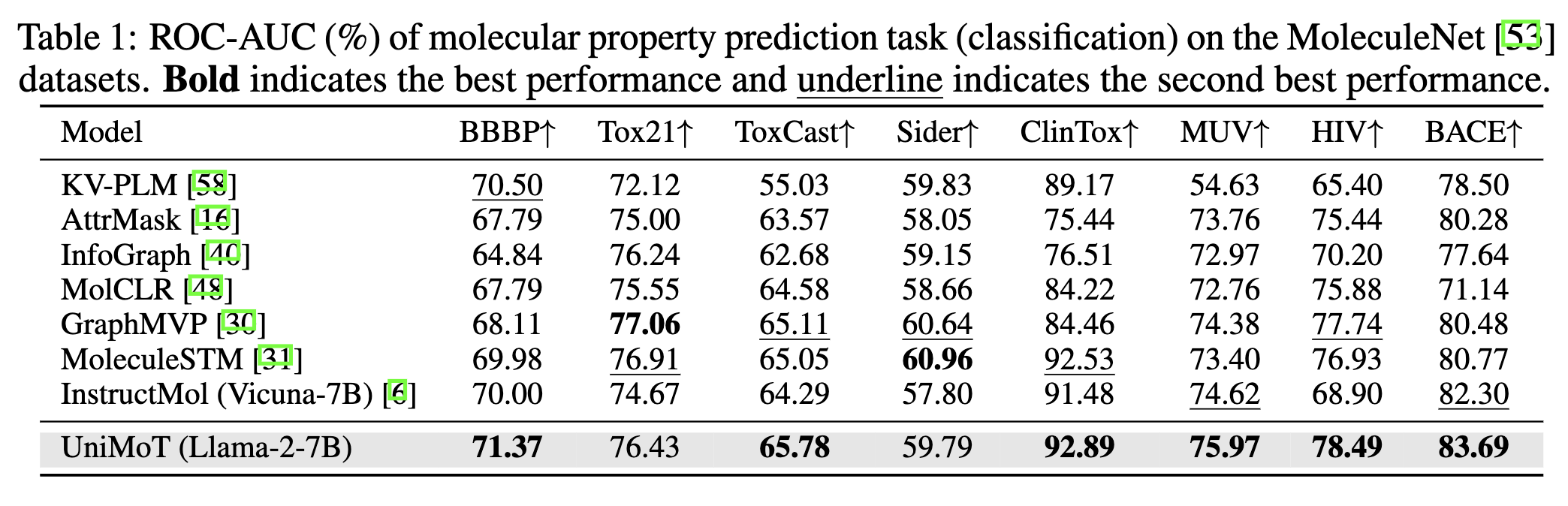
Figure 3. ROC-AUC (%) of molecular property prediction task (classification) on the MoleculeNet datasets.
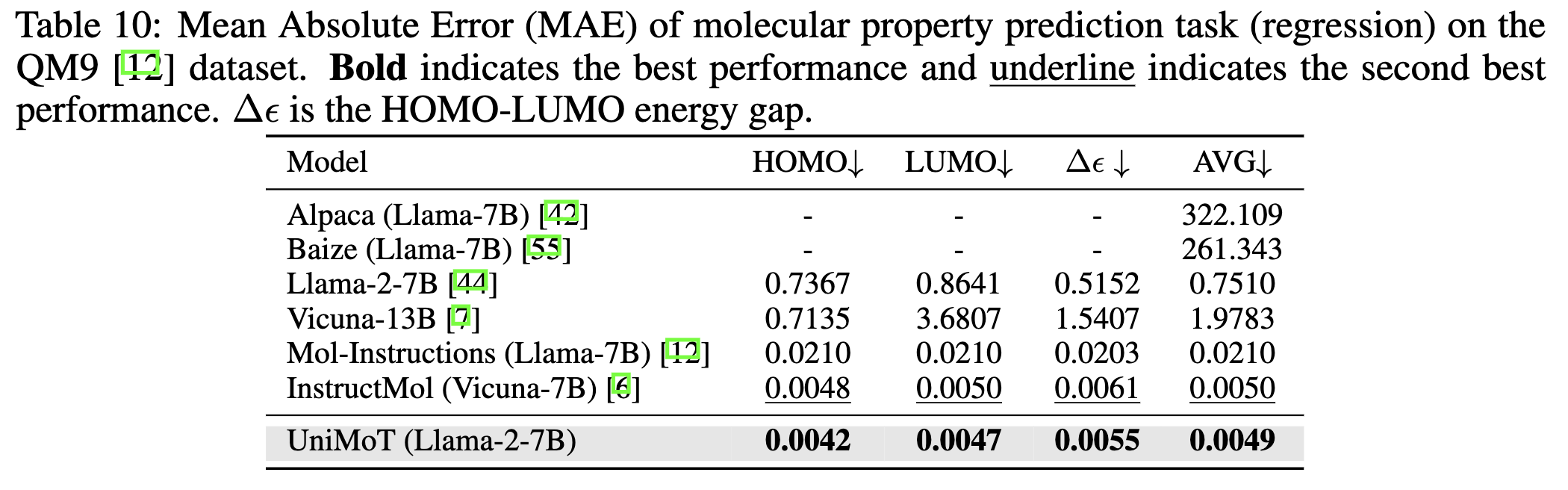
Figure 4. Mean Absolute Error (MAE) of molecular property prediction task (regression) on the QM9 dataset.
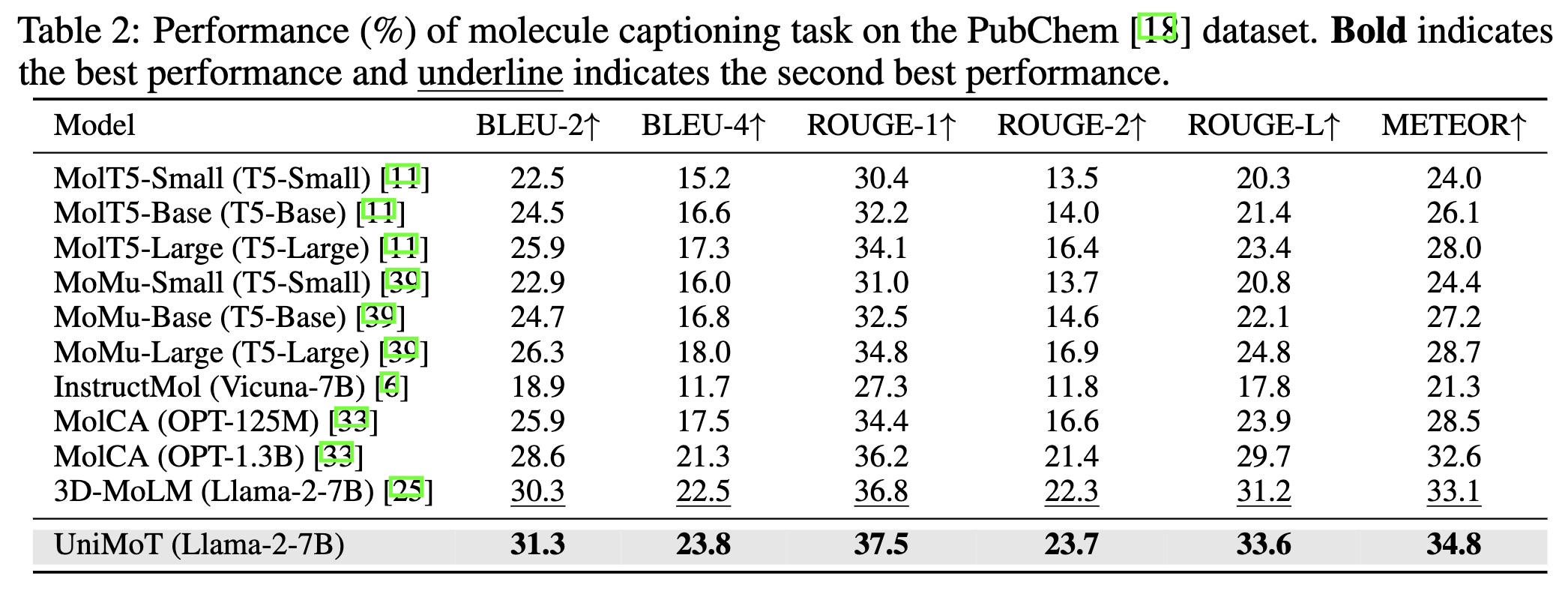
Figure 5. Performance (%) of molecule captioning task on the PubChem dataset.
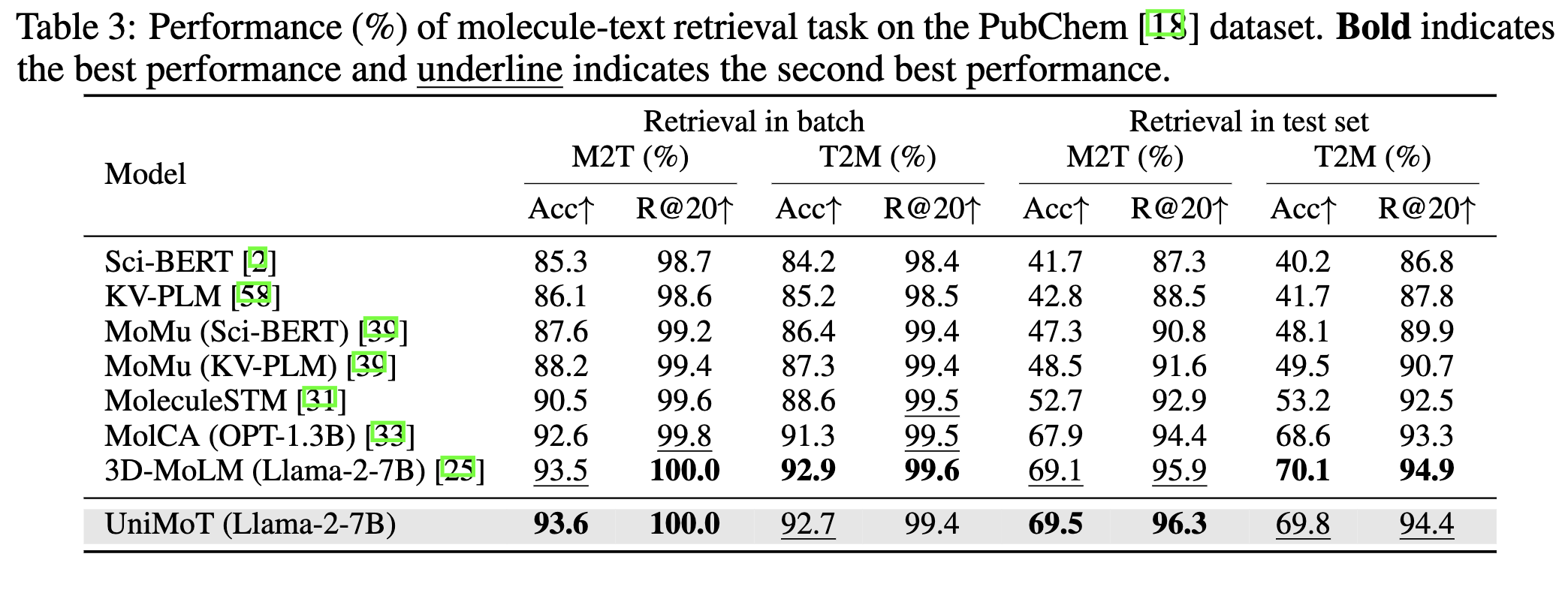
Figure 6. Performance (%) of molecule-text retrieval task on the PubChem dataset.
Molecule Generation Tasks
We employ molecule generation tasks, which encompass caption-guided molecule generation, reagent prediction, forward reaction prediction, and retrosynthesis. UniMoT exhibits the capability to generate valid molecules with a higher degree of similarity to the target molecules compared to the baselines. UniMoT can generate molecules as if they were text, demonstrating strong generation capabilities and providing a new perspective to molecule generation tasks.
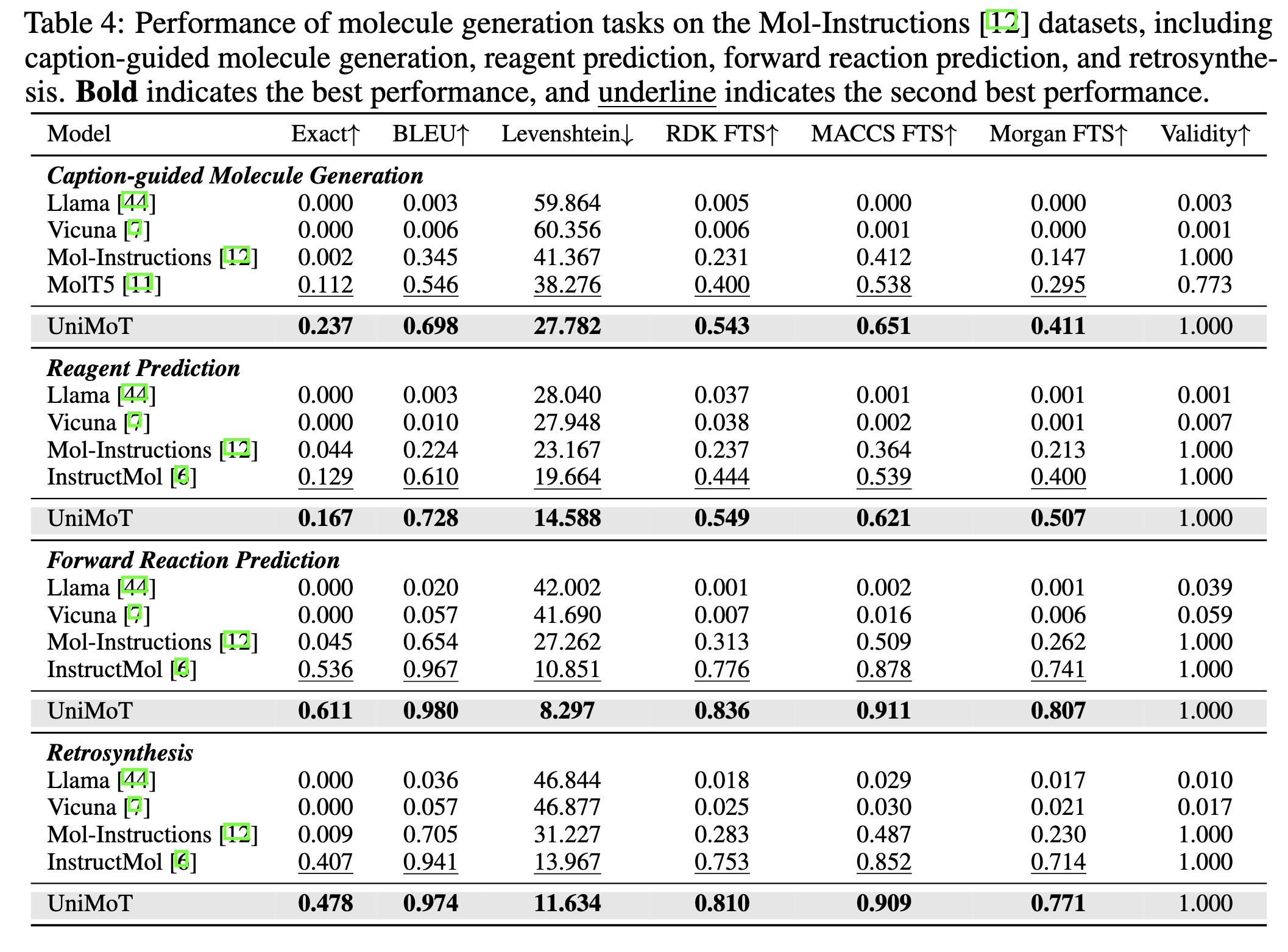
Figure 7. Performance of molecule generation tasks on the Mol-Instructions datasets.
Citation
If you find UniMoT useful in your research, please cite our paper:
@article{zhang2024unimot,
title={UniMoT: Unified Molecule-Text Language Model with Discrete Token Representation},
author={Zhang, Juzheng and Bian, Yatao and Chen, Yongqiang and Yao, Quanming},
journal={arXiv preprint arXiv:2408.00863v1},
year={2024}
}